20230121日志
2023年1月21日
202301,
goroutine停止,
for循环下goroutine闭包,
select多个channel,
noticication channel,
nil channel,
buffered or not buffered channel,
waitGroup,
append是否会导致Data race
golang #
传播不合适的context #
func handler(w http.ResponseWriter, r *http.Request) {
response, err := doSomeTask(r.Context(), r)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
go func() {
err := publish(r.Context(), response)
// Do something with err
}()
writeResponse(response)
}
type detach struct {
ctx context.Context
}
func (d detach) Deadline() (time.Time, bool) {
return time.Time{}, false
}
func (d detach) Done() <-chan struct{} {
return nil
}
func (d detach) Err() error {
return nil
}
func (d detach) Value(key any) any {
return d.ctx.Value(key)
}
- 不合适的context:直接传r.Context()会在writeResponse之后cancel,导致异步任务也被取消
- 自定义context包装parent context,避免使用parent的context并只有Value委派给parent context
没有设计goroutine停止的逻辑(导致可能的内存泄漏) #
ch := foo()
go func() {
for v := range ch {
// ...
}
}()
- goroutine中的ch不知道何时会close, 导致goroutine永远不会退出,导致可能的内存泄漏
func main() {
newWatcher()
// Run the application
}
type watcher struct { /* Some resources */ }
func newWatcher() {
w := watcher{}
go w.watch()
}
- 主线程退出时, 导致goroutine不能优雅的关闭
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
newWatcher(ctx)
// Run the application
}
func newWatcher(ctx context.Context) {
w := watcher{}
go w.watch(ctx)
}
- 使用ctx也不能保证主线程退出时, goroutine能及时处理取消信号
func main() {
w := newWatcher()
defer w.close()
// Run the application
}
func newWatcher() watcher {
w := watcher{}
go w.watch()
return w
}
func (w watcher) close() {
// Close the resources
}
- 正确的方式是实现close方法, 在defer时调用
for循环下的goroutine闭包 #
s := []int{1, 2, 3}
for _, i := range s {
go func() {
fmt.Print(i) // 结果不可预计的,可能是233,可能是333, for循环下的i有相同的内存地址
}()
}
- 解决方案1: shadow i
- 解决方案2: closure接收参数,i通过参数传递
select多个channel #
从哪个channel接收数据是随机的,防止饥饿
单个生产者 #
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
fmt.Println("disconnection, return")
return
}
}
for i := 0; i < 10; i++ {
messageCh <- i
}
disconnectCh <- struct{}{}
- 解决方案1: messageCh使用unbuffered channel, 因为reader为准备就绪时,writer会阻塞
- 解决方案2: 只使用一个channel, 判断channel内的数据走不同的逻辑
多个生产者 #
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
for {
select {
case v := <-messageCh:
fmt.Println(v)
default:
fmt.Println("disconnection, return")
return
}
}
}
}
noticication channel #
var s struct{}; unsafe.Sizeof(s)空结构,占用0字节内存; var i interface{}占用8字节在32位系统,16字节在64位系统
- channnel without data 应该使用
chan struct{}
nil channel #
var ch chan int
<-ch // block forever
ch <- 0 // block forever
nil channel在read,write时都会永久阻塞, select case下不会走这条路径
ch1 := make(chan int)
close(ch1)
fmt.Print(<-ch1, <-ch1) // 0 0
channel 关闭后仍然可以接受数据
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
ch1Closed := false
ch2Closed := false
go func() {
for {
select {
case v, open := <-ch1:
if !open {
ch1Closed = true
break
}
ch <- v
case v, open := <-ch2:
if !open {
ch2Closed = true
break
}
ch <- v
}
if ch1Closed && ch2Closed {
close(ch)
return
}
}
}()
return ch
}
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
go func() {
for ch1 != nil || ch2 != nil {
select {
case v, open := <-ch1:
if !open {
ch1 = nil
break
}
ch <- v
case v, open := <-ch2:
if !open {
ch2 = nil
break
}
ch <- v
}
}
close(ch)
}()
return ch
}
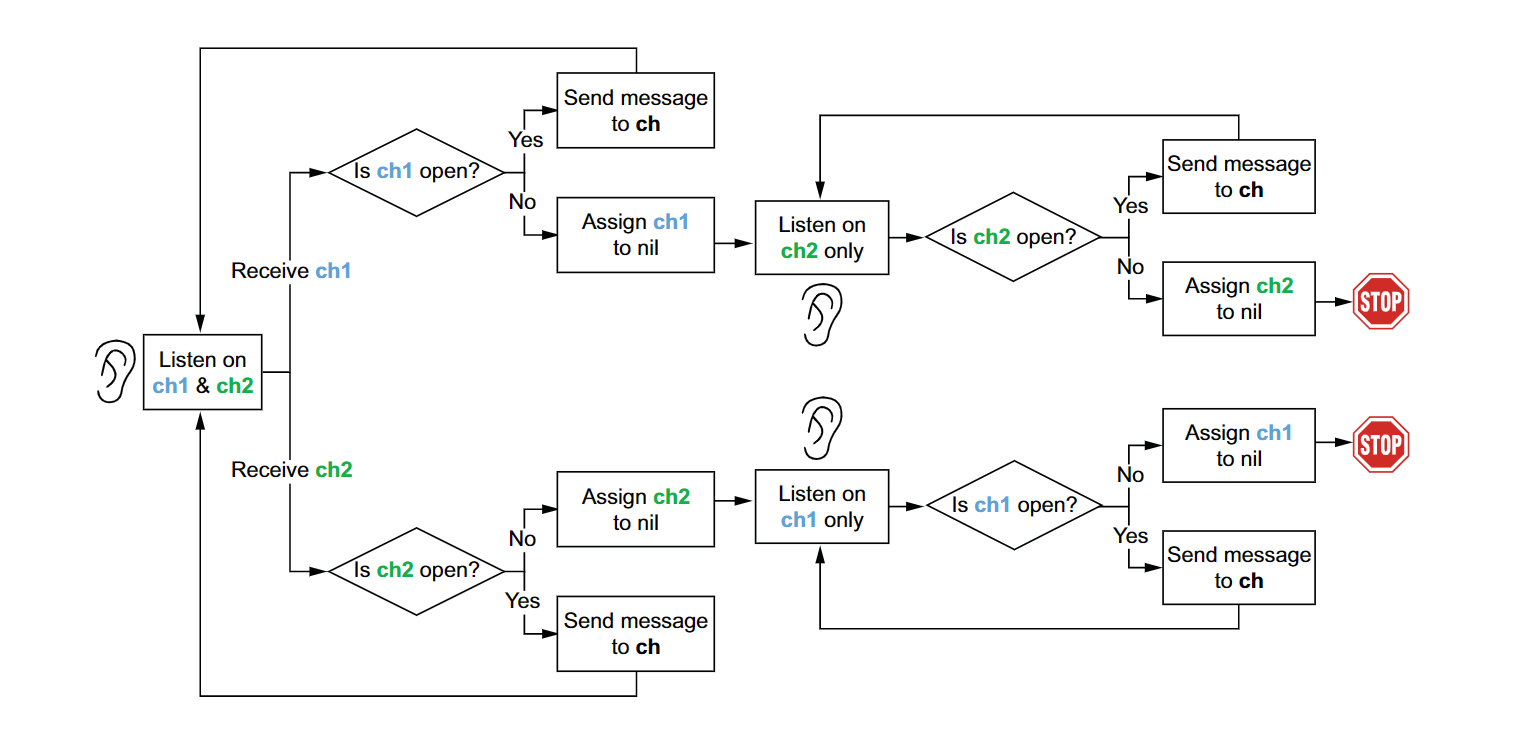
如何选择哪种channel #
- unbuffered channel: 具有同步的功能; notificiation 通过close(ch)
- buffered channel: 通常设置大小为1; worker pool模式,通常设置与goroutine的数量一致; 限制资源利用率,设置为限制的大小; 设置为magic number 40
string format中未预料的副作用 #
type Customer struct {
mutex sync.RWMutex
id string
age int
}
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if age < 0 {
return fmt.Errorf("age should be positive for customer %v", c)
}
c.age = age
return nil
}
func (c *Customer) String() string {
c.mutex.RLock()
defer c.mutex.RUnlock()
return fmt.Sprintf("id %s, age %d", c.id, c.age)
}
append是否会导致Data race #
// s := make([]int, 1) // 不会导致Data race
s := make([]int, 0, 1) // 会导致Data race
go func() {
s1 := append(s, 1)
fmt.Println(s1)
}()
go func() {
s2 := append(s, 1)
fmt.Println(s2)
}()
解决方案
s := make([]int, 0, 1)
go func() {
sCopy := make([]int, len(s), cap(s))
copy(sCopy, s)
s1 := append(sCopy, 1)
fmt.Println(s1)
}()
go func() {
sCopy := make([]int, len(s), cap(s))
copy(sCopy, s)
s2 := append(sCopy, 1)
fmt.Println(s2)
}()
- 不同的goroutine更新相同的index,是data race, 更新不同的index,不是data race
- 多个goroutine,只要有一个goroutine更新map, race detector就会告警,无论是否实际发生竞争
在slice和map并发下 mutext 的错误使用 #
type Cache struct {
mu sync.RWMutex
balances map[string]float64
}
func (c *Cache) AddBalance(id string, balance float64) {
c.mu.Lock()
c.balances[id] = balance
c.mu.Unlock()
}
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
balances := c.balances
c.mu.RUnlock()
sum := 0.
for _, balance := range balances {
sum += balance
}
return sum / float64(len(balances))
}
如果for循环是轻量的
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
defer c.mu.RUnlock()
sum := 0.
for _, balance := range c.balances {
sum += balance
}
return sum / float64(len(c.balances))
}
如果for循环不是轻量的, 只锁定复制的部分
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
m := make(map[string]float64, len(c.balances))
for k, v := range c.balances {
m[k] = v
}
c.mu.RUnlock()
sum := 0.
for _, balance := range m {
sum += balance
}
return sum / float64(len(m))
}
使用waitGroup不当 #
- 注意 wg.Add(1)的位置, 一般不能在goroutine内部